install.packages(c("sfhotspot", "dbmss", "sfheaders"))13 Análisis de patrones de puntos: concentración
NoteResultados de aprendizaje
- R5. Usar paquetes para el análisis espacial en R.
Cuando los datos son ubicaciones de eventos, hablamos de un patrón de puntos. La primera pregunta es si esos puntos se concentran más de lo que esperaríamos por azar.
Usaremos como ejemplo los establecimientos educacionales de la comuna de Concepción.
library(tidyverse)
library(sf)
library(sfhotspot)
library(dbmss)
library(sfheaders)13.1 Preparar los datos: proyección y ventana
Para medir distancias correctamente, los datos deben estar en un sistema de coordenadas proyectado (en metros, no en grados). Usamos EPSG:24879 (UTM para la zona) y filtramos la comuna de Concepción:
comunas <- st_read("data/comunas_biobio.gpkg", quiet = TRUE) %>%
st_transform("EPSG:24879")
conce <- comunas %>% filter(comuna == "CONCEPCION")
colegios <- st_read("data/colegios_biobio.gpkg", quiet = TRUE) %>%
st_transform("EPSG:24879") %>%
st_filter(conce, .predicate = st_within)
nrow(colegios)[1] 12113.2 Densidad de eventos: mapas de calor (KDE)
La estimación de densidad por kernel (KDE) convierte puntos dispersos en una superficie continua de “intensidad”. El paquete sfhotspot lo facilita.
Primero construimos una grilla hexagonal que cubra el área:
grid <- hotspot_grid(colegios, cell_size = 1000, grid_type = "hex") %>%
st_filter(conce, .predicate = st_intersects)Luego calculamos la densidad, ponderando por la matrícula total de cada colegio:
hot_spot_kde <- hotspot_kde(
colegios,
grid = grid,
bandwidth = 2000,
weights = MAT_TOTAL,
kernel = "quartic"
)
ggplot() +
geom_sf(data = hot_spot_kde, aes(fill = kde), color = NA) +
geom_sf(data = colegios, size = 0.4, alpha = 0.5) +
scale_fill_viridis_c(option = "B") +
labs(title = "Densidad de matrícula escolar — Concepción") +
theme_void()
13.3 Hotspots estadísticamente significativos (Gi*)
KDE muestra dónde hay más puntos, pero no si esa concentración es significativa. hotspot_gistar() combina densidad con el Gi* de Getis-Ord:
kde_gistar <- colegios %>%
hotspot_gistar(grid = grid, kde = TRUE) %>%
filter(gistar > 0 & pvalue < 0.05) # solo hotspots significativos
ggplot() +
geom_sf(data = conce) +
geom_sf(data = kde_gistar, aes(fill = gistar), color = NA, alpha = 0.7) +
scale_fill_viridis_c() +
theme_void()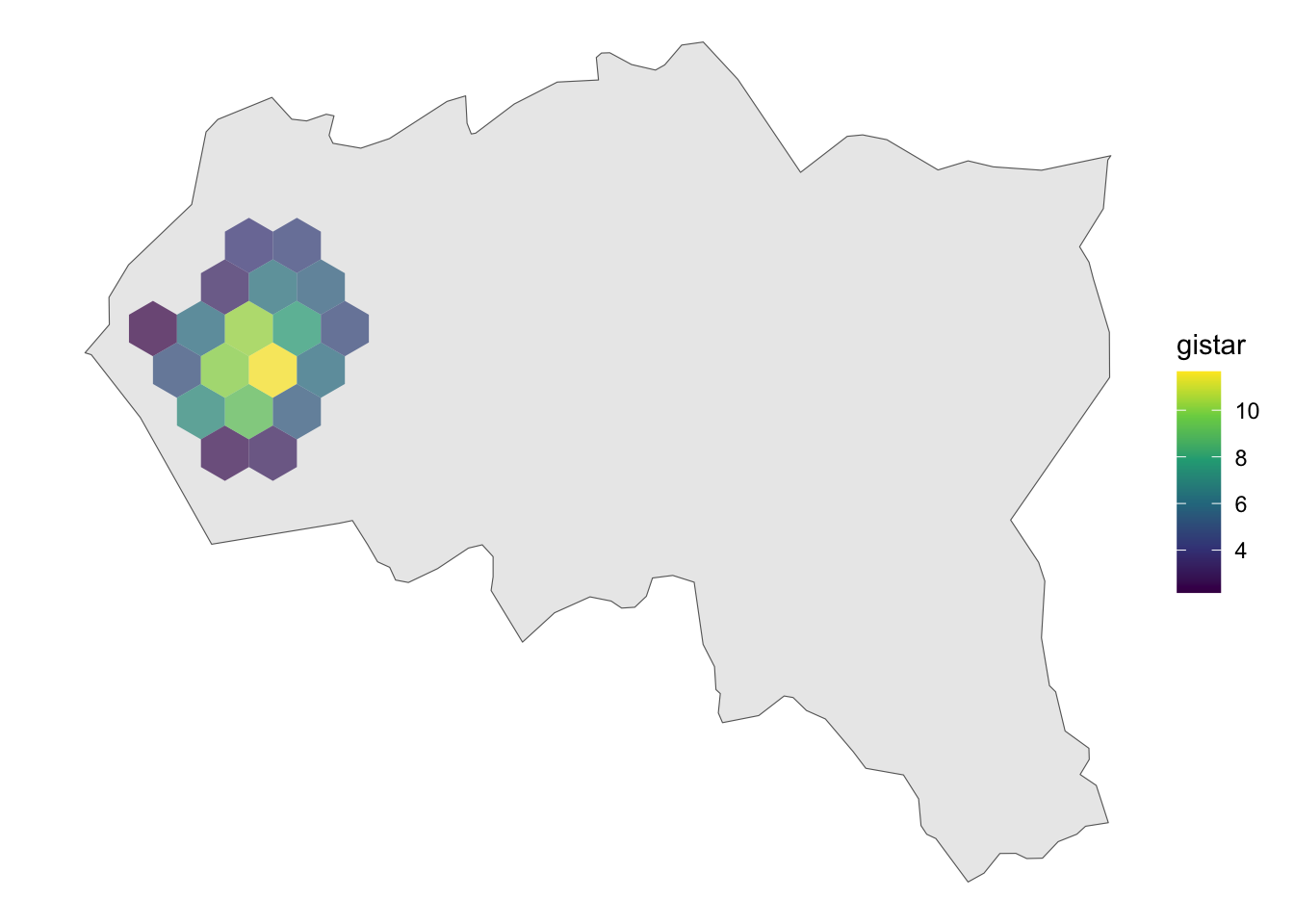
13.4 Funciones de distancia: K, L y M
Las funciones de distancia analizan la concentración a múltiples escalas a la vez. Usaremos dbmss, que requiere convertir los puntos a su formato wmppp dentro de una ventana de observación.
colegios_df <- colegios %>%
sf_to_df(fill = TRUE) %>%
mutate(PointType = "Colegios", PointWeight = 1) %>%
rename(X = x, Y = y) %>%
distinct(X, .keep_all = TRUE)
window <- conce %>% as.owin()
colegios_wmppp <- as.wmppp(colegios_df, window = window)13.4.1 Función K (absoluta)
La función K de Ripley compara el número observado de vecinos a cada distancia con lo esperado bajo aleatoriedad. La envolvente (KEnvelope) genera una banda de confianza por simulación. Si la curva observada queda por encima de la banda, hay concentración a esa escala:
colegios_K <- KEnvelope(
colegios_wmppp,
NumberOfSimulations = 99,
SimulationType = "RandomPosition"
)
autoplot(colegios_K)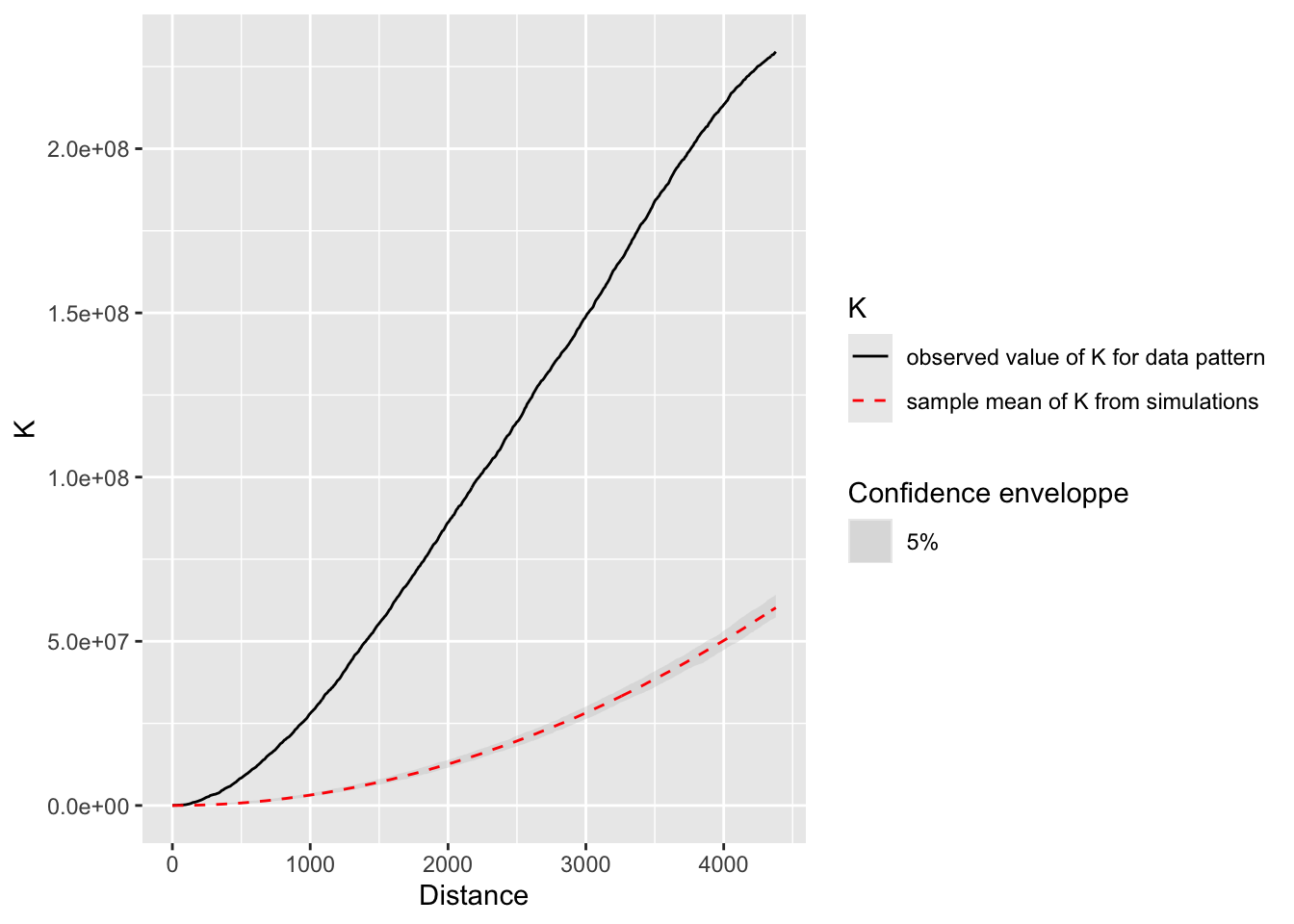
13.4.2 Función M (relativa entre tipos)
La función M mide la concentración relativa de un tipo de punto respecto a otro. Etiquetamos los colegios como públicos vs. privados-subvencionados según su dependencia:
colegios_df2 <- colegios %>%
mutate(PointType = if_else(TIPO_DEPEN >= 4, "Publicos",
"Privados-Subvencionados")) %>%
sf_to_df(fill = TRUE) %>%
mutate(PointWeight = 1) %>%
rename(X = x, Y = y) %>%
distinct(X, .keep_all = TRUE)
colegios_wmppp2 <- as.wmppp(colegios_df2, window = window)
colegios_M <- MEnvelope(
colegios_wmppp2,
NumberOfSimulations = 99,
ReferenceType = "Publicos",
NeighborType = "Privados-Subvencionados",
SimulationType = "RandomLabeling"
)
autoplot(colegios_M)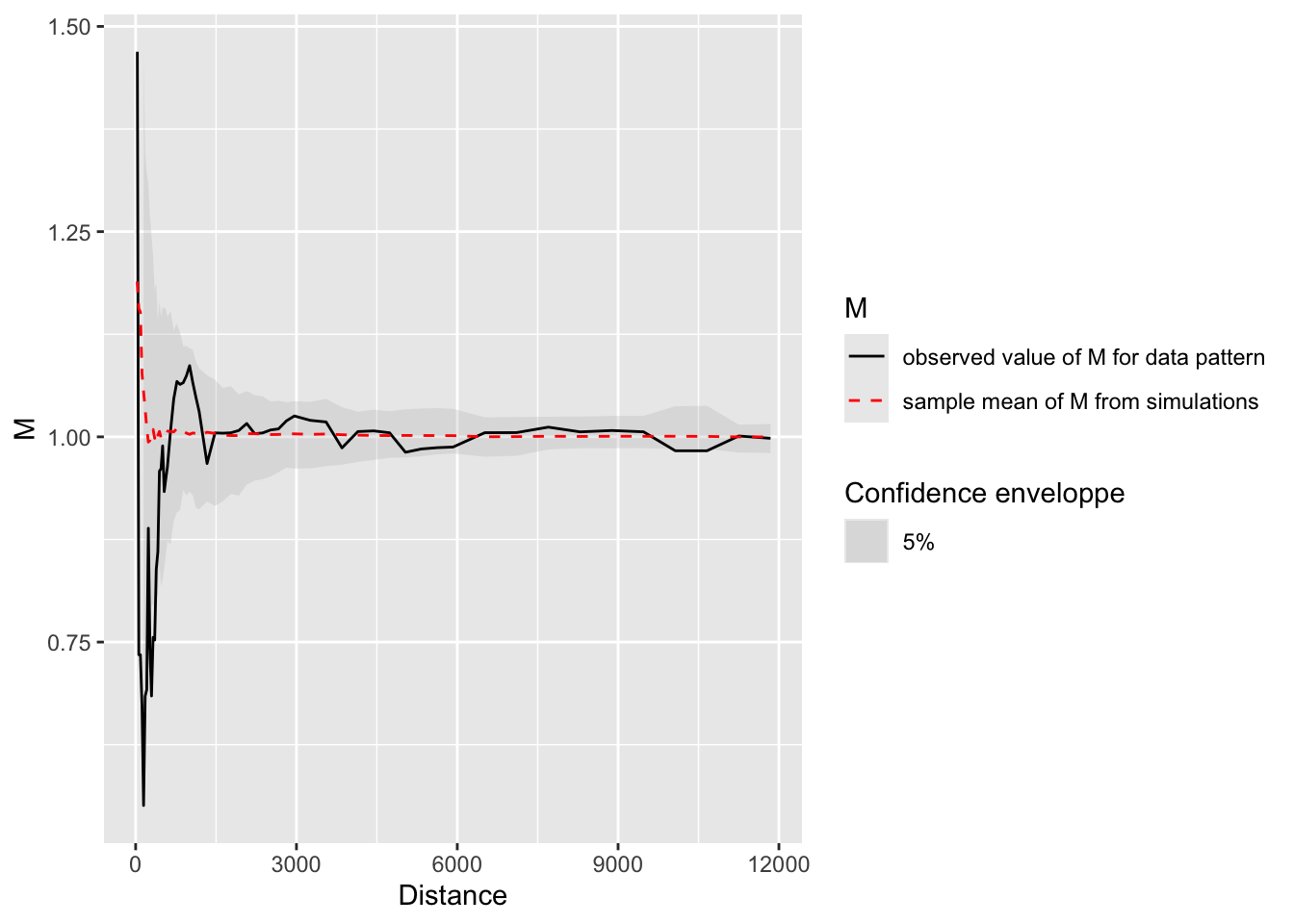
Tip¿K, L o M?
- K / L miden concentración absoluta (¿hay más puntos juntos de lo esperado?). L es solo una transformación de K más fácil de leer.
- M mide concentración relativa entre dos tipos de puntos.
Ejercicios
ImportantEjercicio 13.1 — ¿Se concentran los colegios?
Con los colegios de otra comuna del Biobío (o un conjunto de puntos propio):
- Proyecta los datos y recórtalos a una comuna.
- Construye una grilla y calcula un mapa de densidad (KDE) con
hotspot_kde(). - Identifica hotspots significativos con
hotspot_gistar(). - Calcula la función K con envolvente e interpreta a qué escalas hay concentración.