library(tidyverse)
library(sf)
library(sfdep)11 Indicadores globales de autocorrelación espacial
NoteResultados de aprendizaje
- R5. Usar paquetes para el análisis espacial en R.
Los indicadores globales responden con un solo número a la pregunta: ¿existe autocorrelación espacial en toda el área de estudio? El más conocido es el I de Moran.
11.1 La I de Moran, en intuición
La I de Moran compara el valor de cada unidad con el de sus vecinos. Se interpreta como un coeficiente de correlación:
| Valor de I | Interpretación |
|---|---|
| ≈ +1 | Autocorrelación positiva: valores similares se agrupan (zonas ricas junto a ricas, pobres junto a pobres). |
| ≈ 0 | Distribución aleatoria: no hay patrón espacial. |
| ≈ −1 | Autocorrelación negativa: valores opuestos se alternan (como un tablero de ajedrez). |
11.2 Flujo de trabajo con sfdep
El procedimiento típico tiene tres pasos: definir vecinos, calcular pesos y correr el test.
Usaremos una capa de las comunas del Biobío con indicadores del Censo 2024 (porcentaje de adultos mayores, mujeres e inmigrantes por comuna):
comunas <- st_read("data/comunas_indicadores.gpkg", quiet = TRUE)
# 1. Definir vecindad y pesos espaciales
comunas <- comunas %>%
mutate(
nb = st_contiguity(geom), # vecinos que comparten borde
wt = st_weights(nb) # pesos estandarizados por fila
)
# 2. I de Moran global con prueba de permutación (Monte Carlo)
global_moran_test(comunas$pct_adultos_mayores, comunas$nb, comunas$wt)
Moran I test under randomisation
data: x
weights: listw
Moran I statistic standard deviate = 1.7238, p-value = 0.04237
alternative hypothesis: greater
sample estimates:
Moran I statistic Expectation Variance
0.17928051 -0.03333333 0.01521328 El resultado entrega el valor de I observado, el valor esperado bajo aleatoriedad y un p-valor: si es menor a 0.05, concluimos que existe autocorrelación espacial significativa. En este caso, el envejecimiento de la población sí está espacialmente agrupado entre las comunas del Biobío.
11.3 El gráfico de dispersión de Moran
Una herramienta visual muy útil: en el eje X va el valor de cada unidad y en el eje Y el promedio de sus vecinos (el spatial lag). La pendiente de la recta es la I de Moran.
comunas <- comunas %>%
mutate(
lag_pct = st_lag(pct_adultos_mayores, nb, wt) # promedio de vecinos
)
ggplot(comunas, aes(x = pct_adultos_mayores, y = lag_pct)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE, color = "tomato") +
geom_hline(yintercept = mean(comunas$lag_pct), linetype = "dashed") +
geom_vline(xintercept = mean(comunas$pct_adultos_mayores),
linetype = "dashed") +
labs(x = "% adultos mayores", y = "Promedio de los vecinos",
title = "Gráfico de dispersión de Moran") +
theme_minimal()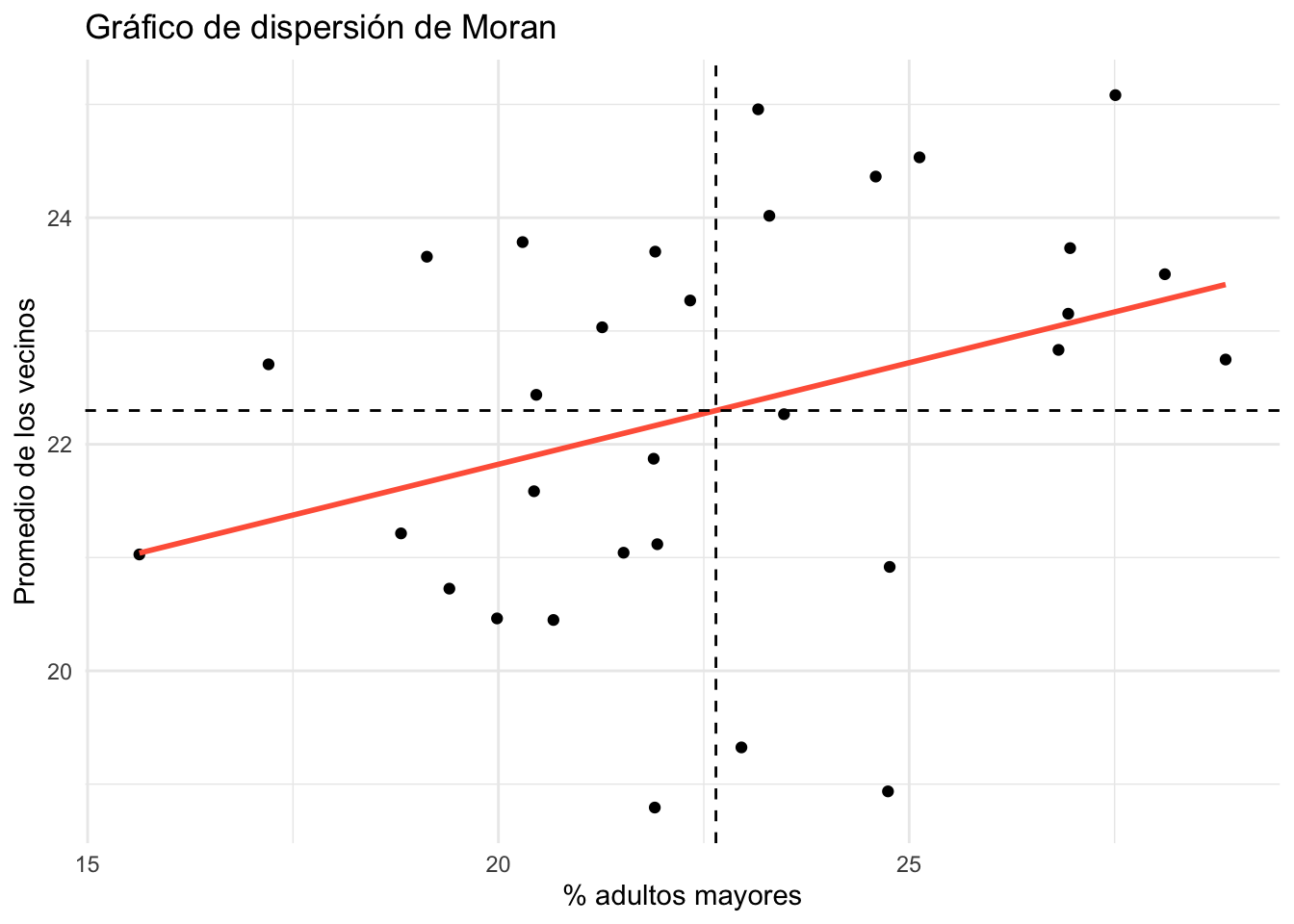
Los cuatro cuadrantes del gráfico anticipan los clusters que veremos en el Chapter 12: Alto-Alto, Bajo-Bajo, Alto-Bajo y Bajo-Alto.
Ejercicios
ImportantEjercicio 11.1 — ¿Hay patrón espacial?
Usando una capa de polígonos con un indicador numérico (puede ser el perfil territorial del Chapter 3 unido a su geometría):
- Construye la vecindad por contigüidad y los pesos espaciales.
- Calcula la I de Moran global con
global_moran_test(). - Interpreta el resultado: ¿el valor de I y el p-valor indican un patrón?
- Construye el gráfico de dispersión de Moran y describe qué cuadrante predomina.